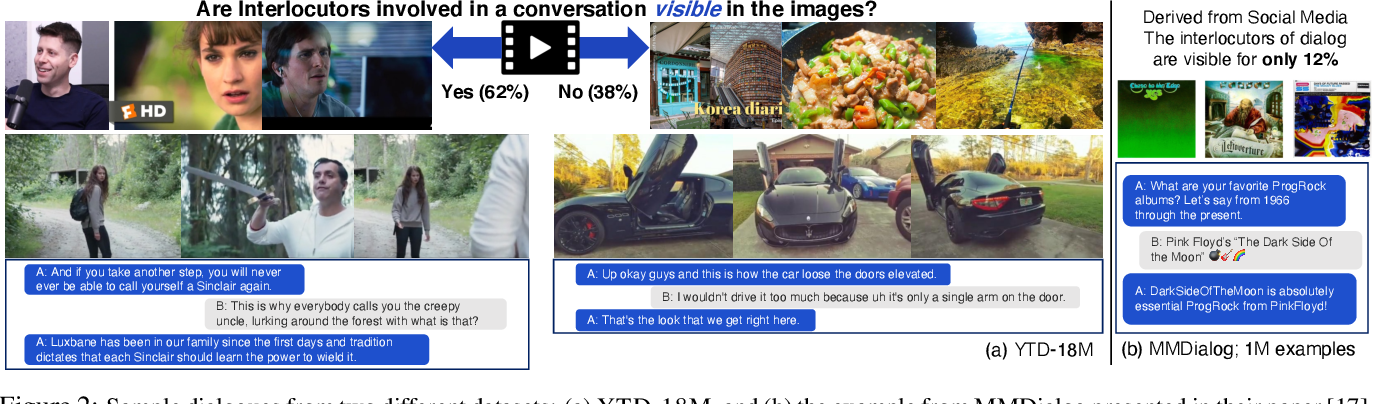
Conversation often relies on non-verbal cues: visual information like physical expressions, body gesture, or the surrounding environment are used by interlocutors to shape and understand meaning. CHAMPAGNE is a generative model of conversations trained on large-scale web videos that can account for visual contexts.