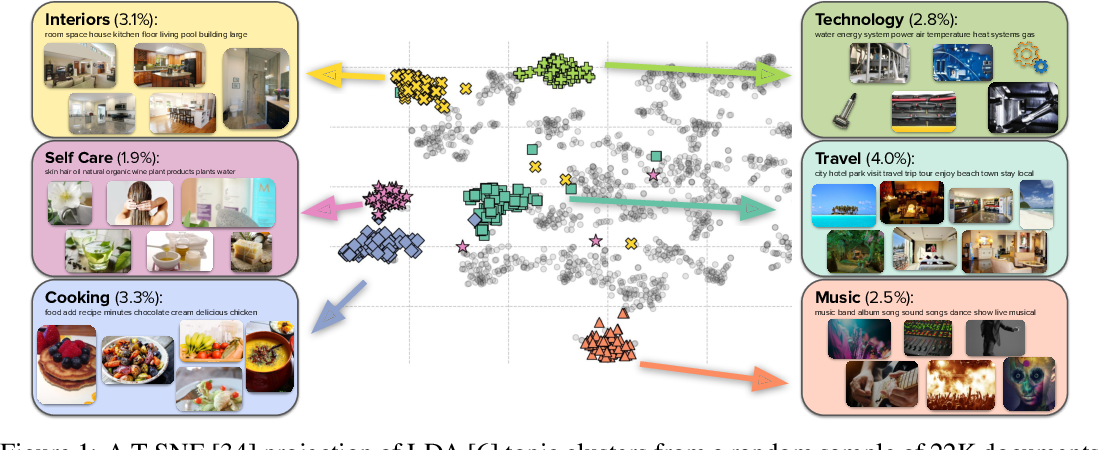
In-context vision and language models like Flamingo support arbitrarily interleaved sequences of images and text as input. This format not only enables few-shot learning via interleaving independent supervised (image, text) examples but also more complex prompts involving interaction between images. Multimodal C4 is an augmentation of the popular text-only c4 corpus2 with images interleaved.